-
- 강재우 고려대 교수 연구팀 ‘Meerkat-7B’, 美 의사면허시험 통과
-
-


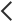



강재우 고려대 교수 연구팀 ‘Meerkat-7B’, 美 의사면허시험 통과
-
기사승인 2024. 04. 11. 15:55
[캠퍼스人+스토리]고려대·아이젠사이언스·I.C.L 공동 연구팀 개발… 74점으로 높은 점수 받아
|

|

11일 고려대에 따르면 연구팀의 Meerkat-7B은 미국 의사 면허 시험에서 74점을 받았다. 60점이 평균 합격선인 미국 의사 면허 시험에서 높은 점수를 획득하면서 그 성능을 입증했다.
Meerkat-7B은 매개변수가 70억개 이하인 소형 언어 모델이다. 소형 언어 모델은 매개변수가 기존 거대 언어 모델 보다 적고, 훈련하는 데 드는 데이터나 시간, 비용이 상대적으로 작다. 또 다른 애플리케이션과 통합하기 쉽다는 장점이 있다.
OpenAI, 구글 등 빅테크 회사들이 주도하는 거대 언어 모델들이 현재 큰 성과를 보이고 있다. 그러나 이는 외부 클라우드를 사용하기 때문에 병원이나 기업 등에서 사용하기에는 민감한 데이터 유출될 위험이 있다는 우려가 있다. 이에 보안성을 높일 수 있는 소형 언어 모델에 대한 수요가 증가하는 추세다.
|
이 외에도 Meerkat-7B는 7개의 의료 벤치마크 성능평가에서 GPT-3.5(175B) 모델보다 평균 13% 높은 성능을 보였다.
강 교수는 Meerkat-7B가 복잡한 의료 문제를 해결하는 데 필요한 다단계 추론 능력을 갖춘 의생명 분야에 특화된 소형 언어 모델이라고 보고 있다. 특히 의생명 특화 언어모델은 병원 내 임상 의사 결정을 지원해 준다. 비표준화된 의료 차트를 정리 해주면서 의료·원무 행정의 효율성을 높여주기도 한다.
강 교수는 "제약 회사에서는 특허 분석, 임상 설계, 문서 작성 등의 노동 집약적이고 전문성을 요하는 업무를 지원해 각 분야 전문가의 업무 부담을 경감하는 데 기여할 수 있다"며 "Meerkat-7B를 통해 새로운 약물 타겟을 발굴하는 과정의 효율성을 대폭 향상시킬 수 있을 것으로 기대한다"고 말했다.
한편 강 교수는 이번 성과를 바탕으로 의료 특화 거대 언어 모델을 활용한 신규 사업을 준비할 예정이다.

댓글
많이 본 뉴스
연예가 핫 뉴스



![[기고] 한의사 활용을 통한 경쟁적 의료제도 구축이 의료..](https://img.asiatoday.co.kr/webdata/content/2024y/04m/29d/20240429010016021_77_50.jpg?c=202404300250?1)
![[단독] 황우여, 골절부상 속 비대위원장 수락 “당 절뚝..](https://img.asiatoday.co.kr/webdata/content/2024y/04m/29d/20240429010016318_77_50.jpg?c=202404300250?1)







오늘의 주요뉴스
- ‘평행선’ 달린 135분…물꼬만 튼 尹·李 소통
- 사회갈등 ‘뼈아픈 대가’…매년 300조 헛돈 쏟아부었다
- 황우여, 부상에도 與 비대위원장 수락…“어찌 고사하나”
- 여야 원내대표 오찬 회동…5월 임시국회 협의는 또 ‘불발’
- 의대교수 휴진 30일 본격화…환자·보호자 피해 더 커질듯
- LG전자, 월풀에 1분기 매출 2조 앞섰다…“세계 가전 1위”
- “국민연금 개혁 골든타임”…정부, 추진단 꾸려 속도낸다
- “분양가 올려볼까”…서울 뉴타운 인기에 인상폭 고심
- 민희진, 어도어 이사회 소집 불응…하이브 임시주총 계획
- 올해 4년제 대학 26곳 등록금 인상…1인당 평균 683만원


-


-
회사소개 | 광고안내 | 구독신청 | 콘텐츠구매 | 제보24시 | 고충처리 | 인재채용 | 사이트맵
회원약관 | 개인정보취급방침 | 청소년보호정책 | 저작권규약
등록번호 : 서울 아00160 | 등록일 : 2006년 1월 18일 | 제호 : 아시아투데이 | 회장ㆍ발행인ㆍ편집인 : 우종순
서울시 영등포구 의사당대로1길 34 인영빌딩 | 발행일자 : 2005년 11월 11일 | 대표전화 : 02) 769-5000 | 청소년보호책임자 : 성희제
아시아투데이는 인터넷신문위원회 윤리강령을 준수합니다.
Copyright by ASIATODAY Co., Ltd. All Rights Reserved

